 住 太陽
住 太陽
検索の文脈におけるエンティティとは、人物や概念も含めた物事やその実体のことをいいます。現在のウェブ検索では、検索クエリの理解や検索結果に表示するウェブページの評価でエンティティが大きな役割を果たしています。この記事では、エンティティとは何で、どう実装されているのかということから、SEOに取り組む立場からエンティティにどう対応すべきかについて解説します。
目次
エンティティとは
SEOの文脈におけるエンティティとは、人物、場所、組織、事物、概念など、他の事物と区別できる一意性を持った物事のことを言います。「単なる文字列ではなく実体」と説明されることもあります。またGoogleはエンティティを指して「トピック」と表現することもあります。
非常に簡単に説明すると、エンティティとは「名前がついていて他と区別できる物事」であり、それらの名前を単なる文字列ではなく実体として理解したものです。Googleの特許文書「非構造化データにおけるエンティティ参照を用いた質問応答」では、エンティティは次のように説明されています。
エンティティとは、一意であり、独自で、明確に定義され、区別可能な事物または概念である。例えばエンティティは、人、場所、物、アイデア、抽象的な概念、具体的な要素、他の適切な事物、またはそれらの任意の組み合わせである。
一般に、エンティティには、名詞によって言語的に表現される事物や概念が含まれる。例えば、色「青」や、都市「サンフランシスコ」や、想像上の動物「ユニコーン」は、それぞれエンティティである可能性がある。
US20160371385A1 – Question answering using entity references in unstructured data – Google Patents1
Googleがエンティティのカタログとして使用するものの中で最もよく知られているのはWikipediaであり、次によく知られているのはGoogleマップです。Wikipediaに登録されている物事や、Googleマップに登録されている場所は、単なる文字列としてではなくエンティティとして理解されます。
まとめると、エンティティとは、他と区別できる名前がついている物事について、その名前を単なる文字列としてではなく実体として理解したものとなります。
エンティティを理解する以前のGoogleでは「住太陽」は単なる文字列でした。しかし現在のGoogleは、いまこの記事を書いている僕という特定の人物として「住太陽」を認識し、識別子 “/g/113z0lh_1” で他のエンティティと区別しています。下のスクリーンショットは僕のナレッジパネルですが、URLに前述の識別子が入っていることがわかります。
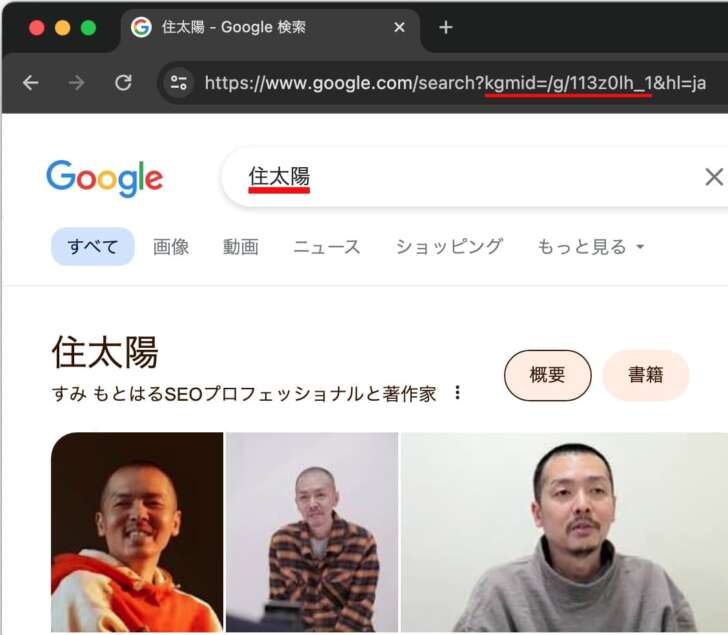
エンティティは言語を超えて一意のものです。このため「住太陽」のエンティティは他言語でも表示が可能です。例えば英語では「Motoharu Sumi」として、アラビア語では「موتوهارو سومي」として、ロシア語では「Мотохару Суми」として表示されます。同じことは「富士山」や「犬」や「台風」や「大谷翔平」などのエンティティでも可能です。
クエリの意図を人間らしく理解する
Google検索ではエンティティのデータを、クエリ(検索キーワード)をより人間らしく理解するために使っています。ユーザーが入力したクエリに含まれる単語やフレーズをエンティティのデータベースと照合することで、ユーザーが探しているものを文字列ではなく現実の物事として理解するのです2。
Google検索は、ユーザーが入力したクエリに含まれる物事(つまりエンティティ)を理解したうえで、ユーザーが使用しているデバイスや、ユーザーがいる場所などから検索の意図を推測し、その意図に合った検索結果を返す、ということをしています。言葉では説明が難しいので例を見てみましょう。
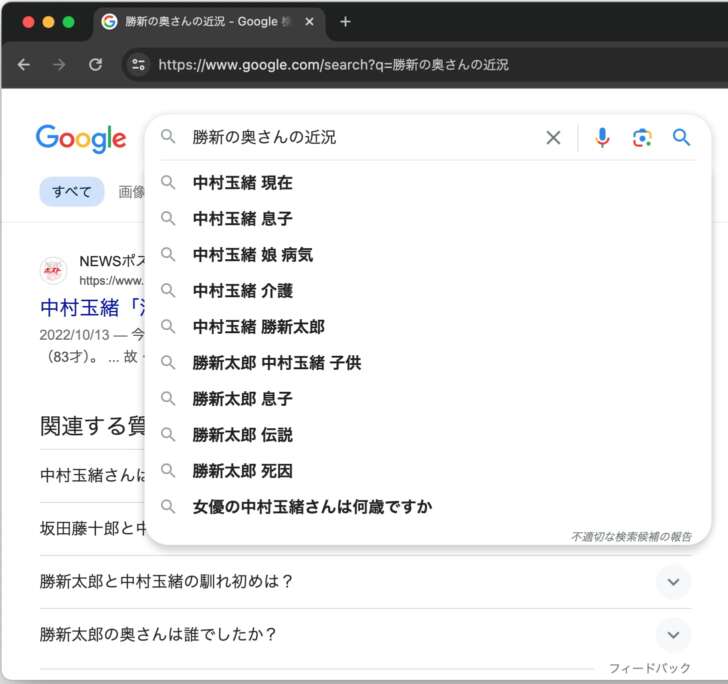
上の画像は「勝新の奥さんの近況」と検索したときの検索結果とサジェストキーワードです。これを見ると、Googleが次のことを理解していることが読み取れます。
- 「勝新」とは俳優で故人の勝新太郎のことである。
- 「勝新の奥さん」は女優の中村玉緒である。
- 「勝新の奥さんの近況」というクエリは中村玉緒やその家族の現在の状況を知りたいという意図である。
Google検索はエンティティを理解することで、クエリの背後にある意図を深く理解し、検索結果を出力します。このようなエンティティの利用は、あくまでもクエリの意図を正確に理解するためのものです。エンティティは検索結果ランキングにも利用されていると考えられていますが、それについては後述します。
Googleが理解するエンティティの増加
前段のようなエンティティを利用した検索意図の理解は、2012年の時点で部分的に実装されていました。ナレッジグラフです。2012年5月16日にGoogleのエンジニアリング担当上級副社長(当時)のアミット・シンガルが公開したブログ記事「ナレッジ・グラフのご紹介:文字列ではなく物事」では、次のように説明されています。
文字列「タージ・マハル」は複数のものを表しています。世界で最も美しい墓廟の1つ、あるいはグラミー賞ミュージシャン、ニュージャージー州アトランティックシティのカジノ、または、あなたの最寄りのインド料理レストラン。文字列ではなく物事。これが、私たちが現実世界のエンティティとその相互関係を理解するインテリジェントなモデルに取り組んできた理由です。
ナレッジグラフでは、ランドマーク、有名人、都市、スポーツチーム、建物、地理的特徴、映画、天体、芸術作品など、Googleが知っている物や人、場所を検索し、クエリに関連する情報をすばやく得ることができます。これは、ウェブの集合的インテリジェンスを活用し、人間と同じように世界を理解する、次世代の検索を構築するための重要な第一歩です。
Introducing the Knowledge Graph: things, not strings3
この2012年の状況と現在の大きな違いは、Googleが知っているエンティティの数が爆発的に増えたことです。上記のブログの時点では5億超のエンティティが認識されていましたが、その8年後の2020年には10倍の50億に増加したと発表4されており、Googleが知っているエンティティの数は増え続けています。
Googleが検索に使用するエンティティのデータはナレッジグラフと呼ばれるシステムに格納されていますが、そこに追加すべきエンティティを収集しているとされるナレッジヴォールトには2024年3月の時点で推定540億のエンティティがあり、中でも人物のエンティティは2020年5月から2024年3月までの4年弱の間に22倍以上に増加5しました。
Googleは人物のエンティティを特定することに熱心で、なかでもライターや著者といった肩書きを持つ人々のエンティティについては特に熱心です。ライターや著者といった肩書きを持つ人々は、それぞれの専門分野でコンテンツを制作します。それらの人々のエンティティを識別することで、検索の精度を向上させることが狙いでしょう。
E-E-A-Tの対象としてのエンティティ
E-E-A-T(経験、専門性、権威性、信頼)はGoogle検索品質評価ガイドライン6に示されているもので、ウェブサイトやコンテンツやコンテンツ制作者を評価する指標のひとつです。専門性の高いコンテンツ、権威性の高いウェブサイト、信頼できる書き手、のような評価を、人間にとってわかりやすく概念化したものがE-E-A-Tです。
ある人物のE-E-A-Tの定量的な計測は、その人物のエンティティが認識されていなければ成立しません。E-E-A-Tとエンティティは、そのどちらが欠けても意味がないものになってしまいます。この意味で、エンティティを認識させることは、E-E-A-Tを高める取り組みに先行するか、同時進行で行う必要がありそうです。
エンティティとE-E-A-Tを切り離すことができないのは人物のエンティティだけではなく、ブランドや、ウェブサイトや、会社や店舗なども同様です。これらのエンティティをGoogleに認識させる方法については後述しますが、レピュテーションやサイテーションやE-E-A-Tは、その対象となるウェブサイトやコンテンツ制作者やウェブサイト運営者といったエンティティと不可分です。
以下の引用に示すように、GoogleはE-E-A-Tのシグナルとしてリンクや言及を用います。このうちリンクについては、従来からのPageRankそのものと考えてよいでしょう。ここで留意しておきたいのは言及のほうです。Googleはリンクをともなわない言及も専門性や権威性や信頼性を示すシグナルとして扱います。
システムは、関連性のあるコンテンツを特定した後、最も役立ちそうなコンテンツを優先しようとします。そのために、どのコンテンツが専門性、権威性、信頼性を示しているか判定するために役立つシグナルを特定します。
たとえば、その判定を支援するために使用している要因の 1 つに、そのコンテンツへのリンクまたは言及が他の著名なウェブサイトに含まれているか把握するということがあります。含まれていれば、多くの場合、その情報の信頼性が高いことを示す十分なしるしとなります。
ランキング結果 – Google 検索の仕組み7
上記の引用では言及を受けるものの例としてコンテンツが挙げられていますが、言及を受けるのはコンテンツに限りません。ウェブサイトや会社などの組織やコンテンツ制作者の言及の対象です。しかし、ウェブサイトや会社やコンテンツ制作者がエンティティとして認識されていなければ、そこにあるのは単なる文字列で終わってしまいます。
ウェブサイトや会社やコンテンツ制作者への言及がE-E-A-Tのシグナルとして機能するためには、それらがエンティティとして認識されていることが必要です。そうでなければただの名前の文字列に過ぎないからです。
Googleはコンテンツ制作者についての詳細なデータを保存していることが、最近流出したGoogleの内部文書によって明らかになっています8。この文書の内容は、コンテンツ制作者のエンティティに対してE-E-A-T(のようなもの)がスコア化されて割り振られ、それが実際の検索に活用されているだろうことを強く示唆するものです。
関連度、注目度、貢献度、受賞歴
公開されているGoogleの特許文書「エンティティ指標に基づく検索結果のランク付け9」では、検索結果のランキングにエンティティを活用する方法が記されています。この方法では、ナレッジグラフのような構造化データだけでなくウェブ上のコンテンツも利用して、エンティティにスコアを割り振ります(下図)。
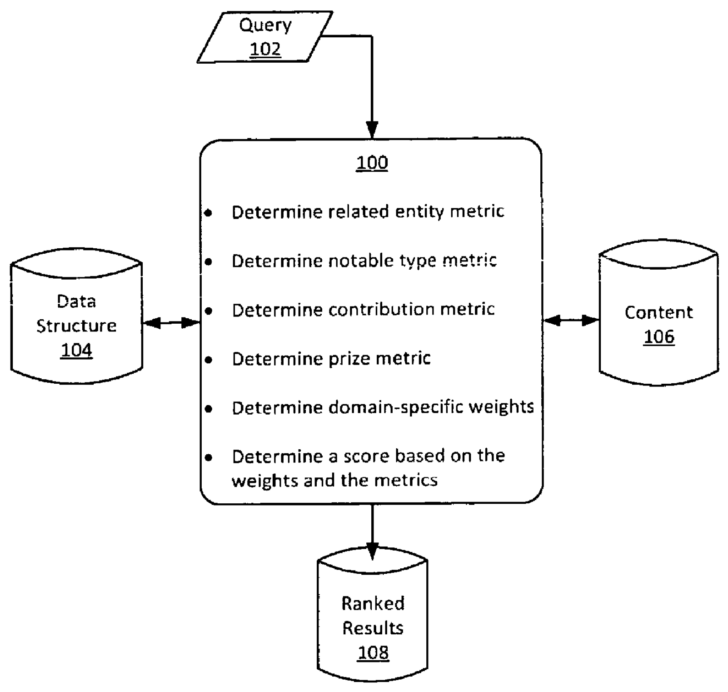
エンティティにスコアを割り振るにあたって使われる指標は、関連度、注目度、貢献度、受賞歴です。そのうえで、与えられたクエリに一致する分野に特有の重み付けを行い、最終的なスコアが算出され、ランク付けされた検索結果を出力します。エンティティのスコアの指標である関連度、注目度、貢献度、受賞歴はそれぞれ次のような意味です。
- 関連度 – エンティティ間の関連度です。たとえばエンティティ「SEO」とエンティティ「住太陽」の関連性はどれほど深いかをスコア化します。
- 注目度 – クエリとして与えられたエンティティが示す分野の中での対象エンティティの人気度です。たとえばクエリが「住太陽」だった場合、SEO分野における「住太陽」の人気度をスコア化します。
- 貢献度 – クエリとして与えられたエンティティが示す分野に対する、対象エンティティの貢献の度合いです。他の専門家による評価や、知名度ランキングの結果などをスコア化します。
- 受賞歴 – その分野における栄誉ある賞を受けたことをスコア化します。たとえば映画界におけるアカデミー賞や、ジャーナリズムにおけるピューリッツァー賞などをスコア化します。
この項で説明してきたことはあくまでも特許文書に書かれていることの概略であり、そのままのものが実際のGoogle検索に実装されているとは限らないことには注意が必要です。しかし、ナレッジグラフとナレッジヴォールトの状況や、Google検索品質評価ガイドラインの内容などを加味すれば、これに近いものが実装されていると考えるのが自然です。

上記はGoogle検索品質評価ガイドラインの目次部分です。これを見ると、ウェブサイトとコンテンツ制作者の評判についての説明が、E-E-A-TやYMYLよりも先行しており、費やされている紙幅も多いことがわかります。評判とE-E-A-Tは、対象となるウェブサイトや人物に対する外部からの評価であるという意味で共通しています。
特許文書の中で注目度や貢献度として説明されている性質や、検索品質評価ガイドラインの中で評判やE-E-A-Tとして説明される性質は、いずれも外部からの評価であり、これが何らかの形でスコアとして計算されている可能性は否定できません。このスコアを構築していく上で必要なことは、対象となる人物やブランドや会社のエンティティを検索エンジンに認識させることです。
エンティティを認識させる
Googleがエンティティの認識を深めている目的は、検索をより人間的なものにすることです。物事を単なる文字列としてではなく実体をともなったエンティティとして理解することによって、より検索者の意図に沿った検索結果を返そうとしています。SEOでは、コンテンツ制作者などの人物や、会社や店、保有するブランドなどを重要なエンティティとして認識させることで、適切な文脈で検索結果に表示される可能性を高めます。
人物やブランドや会社のエンティティが検索エンジンに認識されるためには、ニュースサイトの記事やWikipediaの記事など、ウェブ上の信頼できる情報源から複数回にわたって言及されることが必要です。信頼できる重要な情報源が複数回にわたって言及する人物やブランドや会社は、言及に値する重要なものと考えられるからです。
人物のエンティティを認識させる
ナレッジグラフの初期であれば、人物のエンティティがGoogleに認識されるためには、Wikipediaやスポーツ選手名鑑や出版書誌データベースなど、ごく限られた情報源に人物として掲載される必要がありました。しかし現在のGoogleはもっと幅広く、ウェブ上の様々な信頼できる情報源からエンティティやファクトを収集しています。
人物のエンティティをGoogleに認識させる要件は、信頼性の高い外部のウェブサイト上で言及されることです。大手ニュースサイトやWikipediaをはじめ、業界の有力サイトや地域の有力サイトなどに、その人物の名前が繰り返し現れれば、Googleはその人物のエンティティを認識します。
例えば、有力なニュースサイトの記事の中で、ある人物が何かの功労者として言及されたとしましょう。初めて言及を受けた時点ではGoogleにエンティティとして認識されていなかったとしても、その後、他のウェブ上の信頼性の高い様々な場所で頻繁に言及を受けていれば、どこかの時点でその人物のエンティティはGoogleに認識されます。
ブランドのエンティティを認識させる
人物のエンティティを認識させる場合と同様に、ブランドのエンティティを認識させる場合もまた、外部から言及されることが要件です。もちろん信頼性の高いウェブサイトから複数回の言及を受けることはエンティティを認識させる要件ですが、それほど信頼性の高くない一般の人のブログやSNSで数多く言及されることでもエンティティが認識されます。
iPhoneやヒートテックのような話題性の高いブランドでなくても、ある地域でだけ有名なブランド、ある業界でだけ有名なブランドなども、その地域、その業界の人々から言及される機会が多ければ、ブランドはエンティティとして認識されます。自社が保有するブランドを確固たるものにするためには、ウェブ上で人々の話題になることが重要です。
ウェブサイトのエンティティを認識させる
ウェブサイトもエンティティとして認識させることが可能です。この場合もこれまで述べてきた人物やブランドの例と同様、信頼性の高い外部のウェブサイトから言及されることが重要であるほか、関連する話題を扱うほかのサイトからリンクされることでもエンティティとして認識されやすいようです。
注意点としては、他の既存のウェブサイトと似ていないユニークなサイト名をつけると有利になると考えられることです。外部のウェブサイトからリンクをともなわない言及を受ける場合に、サイト名が普通名詞やその組み合わせのようなありきたりなものだった場合、そのサイトを指した言及であることをGoogleが理解するのが難しくなるからです。
会社や店舗のエンティティを認識させる
会社や店舗のエンティティを認識させるのは比較的容易であるため、特段の話題性を持たない中小企業であってもエンティティを認識させることができます。会社や店舗のエンティティを認識させる最も簡単な方法は、Googleマイビジネスに登録し、Googleのクチコミを集めることです。これはローカルSEOにも効果的です。
会社や店舗をGoogleマイビジネスに登録しただけではエンティティとして認識はされないようですが、公式ウェブサイトが存在していて、Googleマップ上でのクチコミがいくつか(確認できた最低では1つ)つけば、エンティティとして認識されやすいようです。もしGoogleマイビジネス未登録なら、早めに登録し、関係各所にクチコミの投稿をお願いしましょう。
エンティティの認識状況の確認方法
エンティティがGoogleに認識されているかを知る方法はいくつかあり、そのひとつはGoogleトレンド10を使う方法です。Googleトレンドの検索窓にキーワードを入れると、通常は「検索キーワード」として候補が表示されますが、そのキーワードがエンティティとして認識されていた場合「トピック」候補が現れます(Googleはしばしばエンティティのことを一般向けに「トピック」と表現します)。
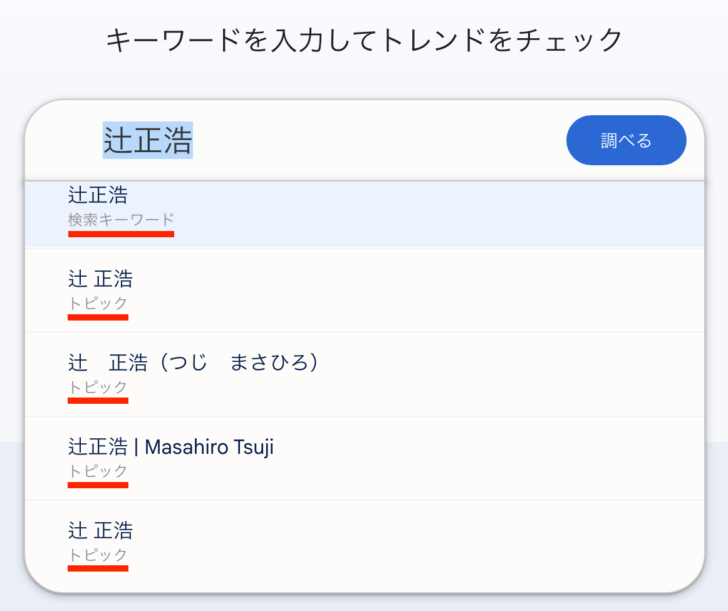
辻正浩11はSEO業界の有名人で、識者としてたびたび新聞やテレビなどのメディアに登場する権威性の高い人物です。ナレッジパネルは表示されませんが、Googleトレンドで見れば上記のように「トピック」候補が表示されており、Googleがエンティティとして認識していることがわかります。豊富な知見を活かした活動の成果です。
なお、上記のスクリーンショットで複数のトピック候補が表示されているのは、ナレッジグラフの中でエントリが重複しているか、または、エンティティとして認識されている辻正浩が複数いることを示しています。このケースではおそらく前者のパターンで、1人の辻正浩に対してエンティティが複数、重複して存在しているのでしょう。
筆者の属するSEOの業界からもう一例見てみましょう。以下はGoogleトレンドの検索窓に「鈴木謙一」と入力したときのスクリーンショットです。「鈴木謙一」は同姓同名の多そうな名前ですから、エンティティとして認識されている候補も複数出てきます。筆者と同じ業界に属する鈴木謙一12はサブタイトルに「SEO」と出ている人物です。
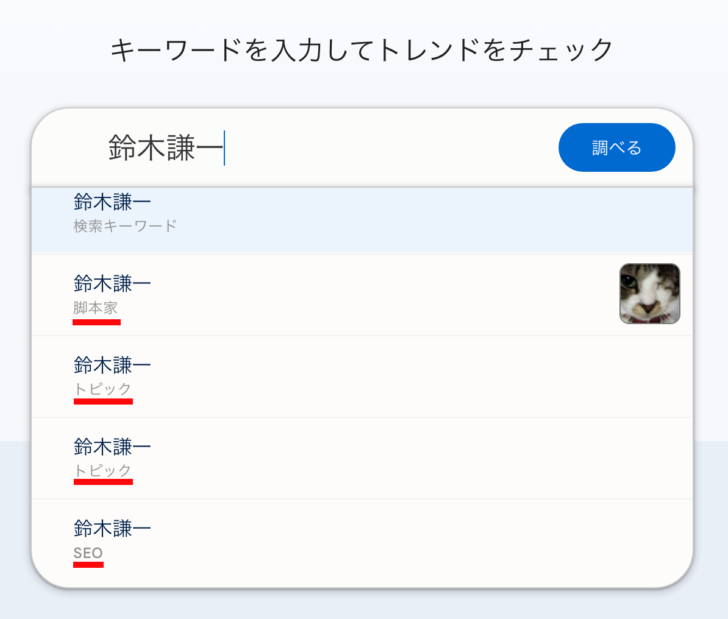
筆者の知る鈴木謙一はSEOや検索周辺の最新の話題をブログ13やXでいち早く伝えているほか、Web担当者Forumで連載「海外&国内SEO情報ウォッチ14」を2009年から担当しているなど、業界内外への貢献度の高い人物です。着実な活動を通じて業界内外に貢献してきたことが、先の辻正浩のケースと共通しています。
人物のエンティティをGoogleに認識させるには、複数の信頼できるウェブサイトから言及を受けることが必要です。そのための確実な方法は、各人が属する業界内での実績をコツコツと積み上げ、実際に言及に足る人物になることでしょう。外部の信頼できるソースからの複数の言及を得るためには、現実世界で実際に信頼されることが必要だからです。
いわゆる「エンティティSEO」について
海外のSEO関連サイトや、少数ですが国内のSEO関連サイトでも、まれに「エンティティSEO」という新テクニックらしきものが紹介されていることがあります。内容をごく簡単に説明すると「コンテンツに関連エンティティを含めるようにすることで、コンテンツのトピックを確実にGoogleに伝え、検索結果での順位向上が期待できる」というものです。筆者は個人的には、これは無意味だと考えます。
ごく普通にコンテンツを制作していれば、そのコンテンツの主題に関連するエンティティは自然に文中に現れるものです。たとえば、ハンバーグのレシピで挽肉(これもエンティティです)を含めないことは不可能でしょうし、不動産物件のコンテンツならその物件の最寄り駅や自治体などは当然の情報として盛り込まれるでしょう。
コンテンツ制作に際して、わざわざ関連するエンティティを埋め込むことを考える必要はありません。ごく普通に、ユーザーにとって有益になるように必要な情報を記述していれば十分です。またそもそも「コンテンツに主題となるエンティティとそれに関連するエンティティを埋め込むとSEOに有利」というアイデア自体が根拠不明であることにも注意が必要です。
エンティティの概念をSEOに役立てる
SEOの実施において意識すべきエンティティは、コンテンツ著者や自社サイト、自社そのもの、保有するブランドなど、自分や自社に関するものだけです。これらのエンティティをGoogleに認識させ、より重要なものとしてGoogleが認識できるように育てていくことはSEOにとって有利に働きます。
もし「エンティティSEO」と呼ぶにふさわしい取り組みがあるとしたら、それは自分や自社のエンティティをより重要なものに育てていくことでしょう。
筆者の取り組みを例にすると、筆者はこのサイトでキーワード「SEO」の検索結果で上位を狙っており、このサイトの外部で「住太陽」と「SEO」が同時に言及される機会を増やす取り組みを続けています。具体的には、外部サイト上での執筆や、外部の団体が主催する講演などです。
そのような取り組みを通じて「住太陽」と「SEO」の結びつきを強化し、「住太陽」が「SEO」に関連する重要なエンティティとして認識されることを狙っています。その結果、このサイトは筆者が一人で運営している小さなサイトでしかありませんが、上場企業やSEO専門の中堅企業と互角に競うことができています。
まとめ
検索エンジンが実世界の物事をより多面的に深く知るようになってきつつある中で、SEOを有利に進めるためには、自分自身や自社や保有ブランドなどを正しくエンティティとして認識させる必要があります。そのうえでエンティティの注目度や貢献度(別の言い方をすれば評判やE-E-A-T)を高めていくことで、適切な場面で検索結果に表示される可能性を高められるでしょう。
もしあなたがまだGoogleに人物のエンティティとして認識されていないなら、すぐにもエンティティの確立に向けて動き出すべきです。また、もしまだ会社や店舗のエンティティが認識されていないなら、まずはそれを優先しましょう。外部からの言及を増やす取り組みがエンティティの認識に寄与し、指名検索の獲得がエンティティの確立に寄与します。
脚注
- US20160371385A1 – Question answering using entity references in unstructured data – Google Patents ↩︎
- How Google Search serves pages – YouTube ↩︎
- Introducing the Knowledge Graph: things, not strings ↩︎
- Google’s Knowledge Graph and Knowledge Panels ↩︎
- Unpacking Google’s 2024 E-E-A-T Knowledge Graph update ↩︎
- Google検索品質評価ガイドライン ↩︎
- ランキング結果 – Google 検索の仕組み ↩︎
- Secrets from the Algorithm: Google Search’s Internal Engineering Documentation Has Leaked – iPullRank ↩︎
- US20150331866A1 Ranking Search Results Based On Entity Metrics(PDF) ↩︎
- Google トレンド ↩︎
- 辻正浩 | Masahiro Tsuji(@tsuj)/ X ↩︎
- Kenichi Suzuki 鈴木謙一(@suzukik) / X ↩︎
- 海外SEO情報ブログ ↩︎
- 海外&国内SEO情報ウォッチ | Web担当者Forum ↩︎